カメラ1台でできる完全自動リアルアバター生成パイプラインを作った
以前、CGで作った人の影を利用したインタラクション作品を作った話を書きましたが、その作品制作の中で写真1枚から人物のアバター生成を行うシステムを開発しました。 今回は、その詳細について書いていきます。 以前の記事はこちら (以前の記事を読んでいない方は、どういう作品を作っていたかをご覧になっていただいてからの方がこの記事の詳細がわかると思います。)
概要
アバター生成パイプラインの全体像としては↓のようになっています。
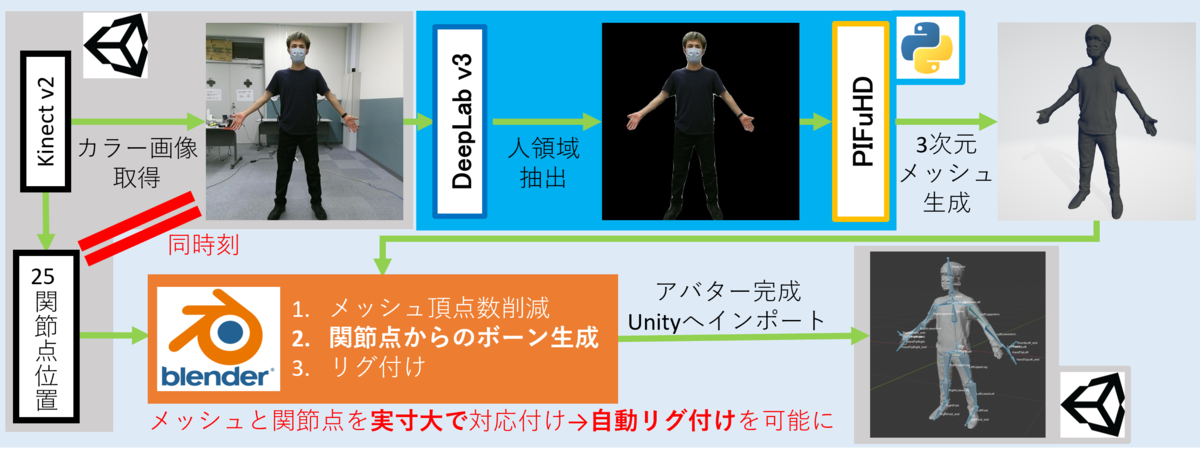
- Kinectでのカラー画像撮影と同時に人骨格点情報を保存
- DeepLab v3のセマンティックセグメンテーションで背景除去
- PIFuHDで3次元メッシュの生成
- メッシュと保存しておいた人骨格点情報からBoneを生成
- リグ付け実行
(作った作品に組み込むことが前提だったので、UnityやらBlenderやらを使っていますが、代替できればなんでもOKだと思います。)
(作ってみた結果として)すごく似ていることをやっている方もいますが、こちらの記事ではメッシュ生成だけでリグ付けされていないので、「アバター」として人の動きを反映させることはできません。 そのため、生成したメッシュと人骨格点情報を実寸大で位置合わせしてからリグ付けするところがポイントとなってきます。 では、各詳細を見ていきます。
Kinectでの撮影
UnityからKinectを動かすために、Kinect for Windows SDKと、KinectのUnityアドオンをこちらから入れます(参考:
UnityでKinectを動かす - Qiita)。
UnityのSceneの任意のオブジェクトにColorSourceManagerとBodySourceManagerスクリプトをアタッチします。
ColorSourceManagerを使って、カラー画像を出力します。
Kinectの画像は上限反転、かつ後述のDeepLab v3用に正方形画像で書き出ししています。
この直後にBodySourceManagerを使って、人骨格点情報をCSVファイルに書き出しています。
CSVファイルのデータは↓のような形になっています。
SpineBase, -0.09998489, -0.21304650, 1.28778700 SpineMid, -0.09860130, 0.11662960, 1.34860800 Neck, -0.09887136, 0.42510210, 1.39316600 Head, -0.06842262, 0.58209430, 1.41956900 ShoulderLeft, -0.25880580, 0.28523010, 1.31506900 ElbowLeft, -0.46841260, 0.29323760, 1.22628400 WristLeft, -0.66610810, 0.31170160, 1.13132700 HandLeft, -0.73187570, 0.31414450, 1.10503800 ShoulderRight, 0.09394829, 0.25767750, 1.43001000 ElbowRight, 0.24875250, 0.14255330, 1.42700800 WristRight, 0.43452660, 0.11693760, 1.43390100 HandRight, 0.48573220, 0.09601390, 1.43826000 HipLeft, -0.18064280, -0.20051540, 1.23052500 KneeLeft, -0.25390640, -0.53377940, 1.14589600 AnkleLeft, -0.06551649, -0.78777150, 0.88342400 FootLeft, 0.00007164, -0.66547630, 0.78344010 HipRight, -0.01332492, -0.21330920, 1.26921400 KneeRight, 0.07572437, -0.54536020, 1.23456700 AnkleRight, -0.27578800, -0.61191820, 1.40525200 FootRight, -0.39934130, -0.55957010, 1.35356100 SpineShoulder, -0.09886321, 0.35052830, 1.38435700 HandTipLeft, -0.79018900, 0.31139960, 1.09132600 ThumbLeft, -0.71317940, 0.34362320, 1.05027300 HandTipRight, 0.56050930, 0.09793835, 1.45274200 ThumbRight, 0.44630720, 0.12957220, 1.42643700
Kinectから取得できる人骨格点の名前、XYZワールド座標となっています。
同時刻のカラー画像と人骨格点情報を保存することで、後述の処理で画像に映った姿でボーンのリグ付けが可能となります。
DeepLab v3とPIFuHDによる3次元メッシュ生成
Kinectの撮影処理の後、カラー画像から撮影対象者のメッシュを作成していきます。 DeepLab v3によって背景を除去し、人領域のみを切り出します。 そして、PIFuHDを使って人領域画像から3次元メッシュのOBJファイルを作成します。
DeepLab v3は、PIFuHDにかける時に背景物体がメッシュとして作られることを防ぐために使っているので、きれいに人領域を抽出できるのであればなんでもOKです。 DeepLab v3、PIFuHDともにPythonで動かしたので、DeepLab v3はPyTorchの機能を、PIFuHDは著者の方が公開しているコードやGoogle Colabのデモなどをそのまま使えば簡単に実装できます。
このあたりのDeepLab v3とPIFuHDを使ってのメッシュ生成は作っていた作品とは別のモジュールとして作成し、gitのsubmodule機能で利用できるようにしました。
あとは、UnityでKinectの撮影が完了後にこのモジュールを呼び出すだけです。 Unity(C#)→Pythonの呼び出しは、C#の外部プロセス呼び出しの機能を使っています。 (参考にしたサイト: C#からPythonを実行する方法【Unity】 - トーフメモ)
コードはこんな感じ↓
using System.IO;
using System.Diagnostics;
using UnityEngine;
~~~
bool RunProcess(string exe, string args, string workDir){
try{
//外部プロセスの設定
ProcessStartInfo processStartInfo = new ProcessStartInfo() {
FileName = exe, //実行するexeファイルのpath
UseShellExecute = false,//シェルを使うかどうか
CreateNoWindow = true, //ウィンドウを開くかどうか
RedirectStandardOutput = true, //テキスト出力をStandardOutputストリームに書き込むかどうか
RedirectStandardError = true, //エラー出力をStandardOutputストリームに書き込むかどうか
Arguments = args, //実行するスクリプト 引数(複数可)
WorkingDirectory = workDir
};
var process = new Process();
process.StartInfo = processStartInfo;
// 非同期での出力と終了検知の設定
process.EnableRaisingEvents = true;
//外部プロセスの開始
process.Start();
//ストリームから出力を得る
var output = process.StandardOutput.ReadToEnd();
var error = process.StandardError.ReadToEnd();
var exitCode = process.ExitCode;
//外部プロセスの終了待ち
process.WaitForExit();
process.Close();
//ログ出力
if(!string.IsNullOrWhiteSpace(output)) UnityEngine.Debug.Log(output);
if(!string.IsNullOrWhiteSpace(error)) UnityEngine.Debug.LogError(error);
return exitCode == 0;
}
catch(System.Exception e){
UnityEngine.Debug.LogError(e);
return false;
}
}
メッシュと、保存したCSVファイルからのリグ付け
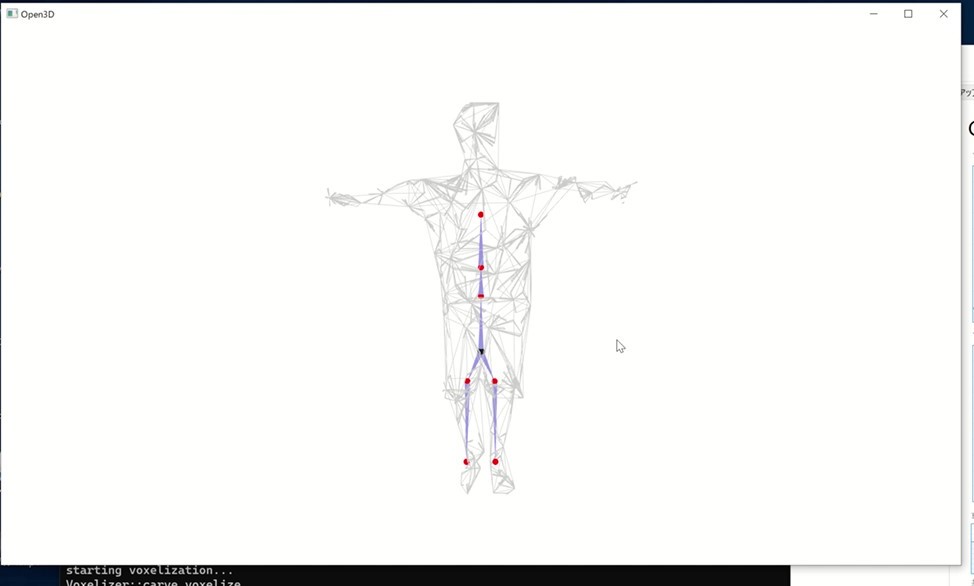
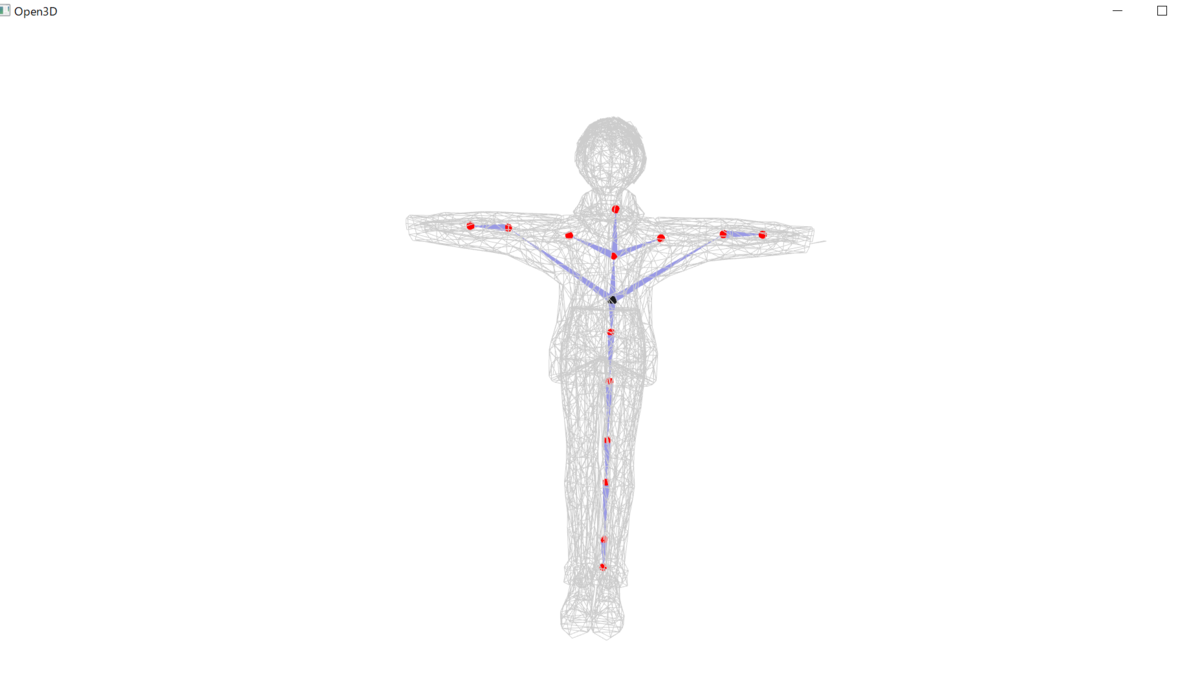
メッシュ生成が完了したら、Kinectでの撮影時に保存しておいたCSVファイルの人骨格点情報と組み合わせて、リグ付けを行っていきます。 このリグ付けをどうするかをかなり悩んでいたら、どうもPIFuHDが出力するOBJファイルのスケールが実寸のサイズであることに気づきました*。 そのため、せっかくKinectを(作品内で)使っているなら、人骨格点情報と紐づけて自前でリグ付けができるのではないかという考えになりました。 このことが、メッシュ生成元のデータであるカラー画像と、リグ付けするBoneの元データの人骨格点情報を、Kinectでの撮影時に同時に記録している理由になります。
*(もっと正確に言えばKinectの人骨格点情報のポジションをメッシュ上に配置してみると、メッシュの関節部分と見た目上ほぼ一致していたというのに気付いただけなので、PIFuHDが出力するOBJファイルのスケールが実寸のサイズであるという確証はありません。論文をきちんと読めばそのあたりが書かれているかもしれませんが...)
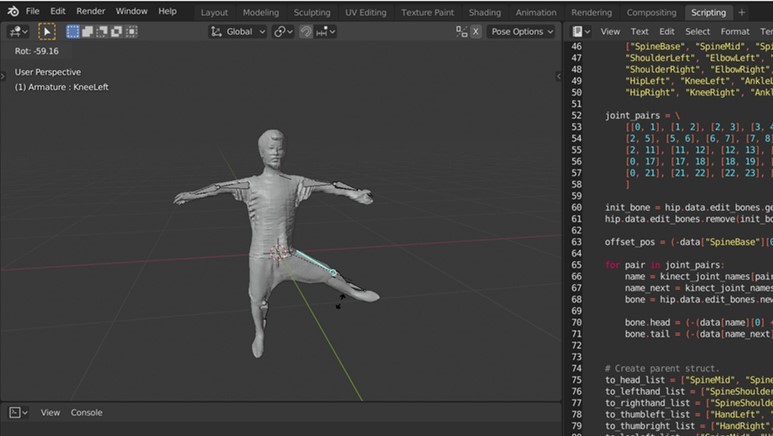
となると、あとは実装するだけです。 リグ付けにはBlenderを使っています。 BlenderではPythonを動かすことができて、手動のGUI操作で行っていることはPythonプログラムファイルを用意してBlender上で同様の操作が可能です(使い方はこの辺とかを見てください)。BlenderのAPIについてはこちら
また、
<Blenderのpath>/blender.exe --background --python hoge.py
のような形でCUI操作で、Blenderのウィンドウを開かずにバックグラウンドモードで指定したPythonスクリプトを実行することもできます。 なので、先ほどのUnity→Python呼び出しと同じようにするだけでUnityからBlenderを呼び出してリグ付けされたFBXファイルを生成することができます。
さて、肝心のリグ付け処理ですが、↓のようになります。
無事にリグ付けが完了したらFBXファイルが作成されます。
開発中の様子は↓。
選択したボーンを動かすとメッシュも動かせています。
Unityに戻す
以上で撮影、メッシュ生成、リグ付けができました。 作った作品では、リアルタイムで撮影、メッシュ生成、リグ付けを行った後、生成したFBXファイルのアバターをUnity上で動かす必要がありました。 そのため、メッシュ生成とリグ付けの外部実行プロセスについては非同期処理でメインスレッドと別スレッドで動かすことで、アバター生成中もUnityが止まらないようにしてチュートリアル動画の閲覧などを可能にしました。
アバター生成が完了したあと、UnityのC#でAssetDatabase.Refresh()メソッドを呼ぶ必要があります。
生成したFBXファイルはUnityのAssetsフォルダに配置しただけではリアルタイム実行中には認識されません。
そのため、AssetDatabase.Refresh()メソッドを呼ぶことでAssetsフォルダの更新を行います。
また、Assetsフォルダに配置したFBXファイルをHumanoidモデルとして認識させるためにも一苦労必要です。
↓のようなスクリプトをAssetsフォルダにおいておくことで、対象のFBXファイルをHumanoidとして認識させてあげる必要があります。
using UnityEngine;
using UnityEditor;
public class AvatarImportSetting : AssetPostprocessor
{
// Unity EditorでAseetsが新規にインポートされたら呼ばれる
void OnPreprocessModel() {
ModelImporter importer = (ModelImporter) assetImporter;
var avatarFbxPath = "Assets/KinectAutoRig/Avatar.fbx";
// Blenderで生成したFBXファイル以外なら破棄
if(avatarFbxPath != importer.assetPath) return;
// FBXファイルをHumanoidとして設定
// FBXファイルのImport Setting > RigでHumanoidを選ぶのと同じ
importer.animationType = ModelImporterAnimationType.Human;
Debug.Log(importer.assetPath + " is imported as Humanoid model.");
}
}
あとは、AssetDatabase.LoadMainAssetAtPathメソッドを使ってUnityのシーンに配置したり、Kinectでモーションキャプチャをしたりと、好きに使うだけです😊
つまづいたこと
GPUメモリ
Deep Lab v3、PIFuHD、Unityと、GPUを使っての計算が多くなります。 とくにDeep Lab v3、PIFuHDではGPUメモリの容量が十分に大きくないと実行中にメモリ容量が不足してこけます。 私が最初に実行した環境だとRTX2080 superを載せているデスクトップPCなのですが、8GBメモリでも落ちてしまいました。 普段使いの関係ないアプリケーションをすべて終了させて、0.6GBの状態から実行すると最大で7.6GB近くまでメモリ容量を消費したので、メモリ容量が大きいGPUじゃないとつらいです...
安定性
長々と説明していましたが、実はこの方法は100%アバターを作れるほどの精度はないです...。 Kinectでの撮影の環境によって、PIFuHDのメッシュ生成精度やボーンの配置位置が不安定で、リグ付けがうまくいかない時があります...。 これでも、Blenderでの処理で重複頂点を減らしたりして大幅に安定性は向上したのですがね...
いろいろ試していたこと
RigNet
リグ付けをどうやって自動で行うのかをかなり悩んでいたのですが、Kinectの人骨格点情報を使う考えの前はRigNetの使用を考えていました。
RigNetはSIGGRAPHで発表された機械学習手法によってリグ付けを行う手法で、こちらを参考にして試してみました。
RigNetが入力として受け付ける頂点数が少ないためPIFuHDで生成したメッシュの頂点数をかなり減らして入力したためか、あまり精度が出なかったです...
あとは、実行時間も4~5分とかなり待ち時間が必要なので、今回制作した作品には使えないと判断しました。
PIFuHDのメッシュだと難しいのかなと思って、VRMモデルを入力したりしてみても、足や頭が正しくリグ付けできていなかったりと、あまり精度はよくない結果になりました(これも頂点数が多すぎかも?)
頂点カラーで色付けしてみたら...
冒頭でも述べたすごく似ていることをやっている方の記事をみたら、メッシュに頂点カラーで色付けをしていました。 自分の手元のPIFuHDで生成しているOBJファイルをテキストエディターなどで覗いてみると、
v -0.5899 0.1797 0.0039 0.2286 0.9002 0.3727 v -0.5898 0.1797 0.0035 0.2273 0.8982 0.3694 v -0.5898 0.1797 0.0039 0.2341 0.9026 0.3689 ...
となっているので、この記事と同じだと思い、自分のパイプラインにも色付けを組み込もうとやってみました。 BlenderでのOBJファイル読み込みの後に、色部分の値を自前でパースして、各頂点に色付け処理を組み込みました。 コードはこちら↓
で、実行してみたら...
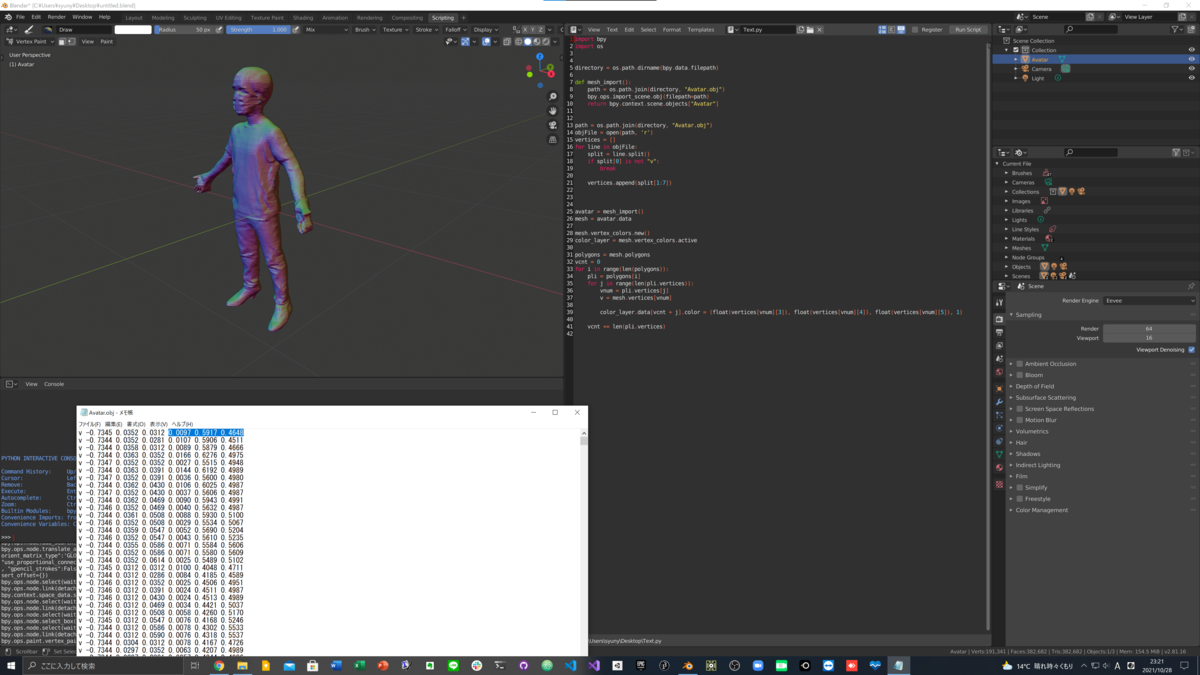
なんと、法線だったようです...(笑)
調べてみると、PIFuは頂点カラーのようですが、PIFuHDは法線のようでした...(そもそも、2つは別のものだったと初めて知った...) 私が制作した作品ではシルエットだけが必要だったので問題なかった(興味本位でやっていただけ)ですが、アバター生成パイプラインのPIFuHDのところをPIFuに変えたら、理想的なリアルアバターになりそうですね...
まとめ
ということで、1回写真を撮るだけで完全自動で自分の分身のアバターを生成できるパイプラインを開発しました!! 自動リグ付けで検索すると、Adobe mixamoやAutoRigのようなツールも見つかりますが、これらは肘や膝などの位置を手動で選択する必要があります。 この操作すらもなく、リグ付けできる仕組みは聞いたことがなかったので、個人的にはかなり面白い経験ができました。
Kinectやら、Pythonやら、いろいろツールを使っていますが、各ツールは置き換え可能で、処理の流れ=パイプラインさえ一緒だったらいろんなところで使えるのではないかと思います。とくに、KinectをMediapipe Poseに置き換えたら、誰でも持っているWebカメラで作れるのでかなり便利かと思います。 (IKEPはMediapipe PoseのUnity移植版も開発したので、ぜひ~!←宣伝w)
メタバース時代がやってきているのでもっと精度が上がれば、お気に入りのアバター以外にも、誰もが自分のリアルアバターでメタバース生活を送る選択肢ができそうで非常に楽しみです😊
「駆け出しだった大学生」がVRコンテストで2作品作って準優勝したお話
今年、IVRC 2021 (Interverse Virtual Reality Challenge)に参加してVR、インタラクティブ作品を制作しました。
約半年の活動がようやく落ち着いたので、その活動について書きます。

IVRCとは
IVRC(Interverse Virtual Reality Challenge)のサイトに書いてあるとおりなのですが、
IVRCは1993年から続く、学生を中心としたチームでインタラクティブ作品を企画・制作するチャレンジです。VRを取り巻く環境が大きく変化した2020年、次の時代のVRコミュニティを生み出すため、大きく変わりました。
Interverse Virtual Reality Challengeとあるように、つまりはVRとかHCIなどの作品を作ろうという、主に学生向けのチャレンジ、コンテストです。 ただ、個人的にはただ単純なVRやHCIの作品でOKという感じではなく、新しい何かが存在する作品を作ろうという印象があります。
IKEPとIVRC
実は私自身はIVRCに出場するのは初めてではなく、2017年にも出場していました。 その時のこともこちらに書いてます(これがあったので本記事のタイトルに「駆け出しだった大学生」を入れたw)。 当時はプログラミングも初めて半年ほどで、未熟だったためIVRCに参加できたのはマグレだったのですが、他の人たちの作品に圧倒されたのをよく覚えていますw ただ、この時からVRが面白いと思ってVRを中心にモノづくりにのめり込むようになったので、いい思い出です。
2017年の翌年の2018年も応募はしていたのですが書類選考で落ちたので、4年ぶりのIVRC参加となりました。
#IVRC2021 とIKEP
— IKEP (@CreativeIKEP) 2021年11月6日
2017年、初めて出場して周りに圧倒されて落ち込む
↓
2018年、書類落ち
↓
2021年、総合2位!
ドラマの世界にいるみたいな感じ...😊
また、プライベートでもIVRCのコミュニティを通して大きな進展があったので、個人的には非常に思入れの強いコンテストです(IVRCに関わっている方々に本当に感謝です)。
なんで、再び参加したの?
友人がIVRCに参加しようかなと考えているのを聞いて、面白そうだから企画アイデアだしの話だけ聞くかと顔を出しただけでした。 その結果、思った以上に面白いものを作ることになり、これは参加するしかないとなったからですw
その友人自身は学生最後だからというのもあったそうですが、自分も少しそういった考えもあったかもしれません。
企画アイデアだしと企画書応募
自分を含め5人のメンバーが集まりました。 コロナ渦ということもあり、リモートで企画アイデアだしをしました。 zoomで話しながらとmiroにそれぞれのアイデア(単語レベルのアイデア)を書いて、その後、面白そうなものをそれぞれがピックアップしました。 ピックアップしたものを組み合わせたり、そこからさらにアイデアを派生したりして、作品のコアとなる新しい体験を考えました。 ある程度体験させたいことが決まったら、それが現実的に・技術的に可能かどうかを検討してOKなものを企画書として提出することにしました。
企画アイデアだしの結果2つの企画まで絞ったのですが、どちらもアイデアを捨てるにはもったいないぐらい面白いと考え、どちらかが企画書選考を通過すればラッキー!ぐらいの気持ちで2作品分の企画書を提出しました。
結果、どちらの企画も企画書選考を通過しました🎉 制作・開発の期間やチームメンバー個々人の大学生活との掛け持ちを考えても2作品両方を制作するのは、大変なのは目に見えていましたが、「せっかくなら」という気持ちと、体験のコアとなる部分は最低限作れるだろうという考えで、2作品を作成することにしました(実際、めちゃくちゃ時間をとられたので、大学生活などとの掛け持ちにかなり苦労した...)
何を作ったの?
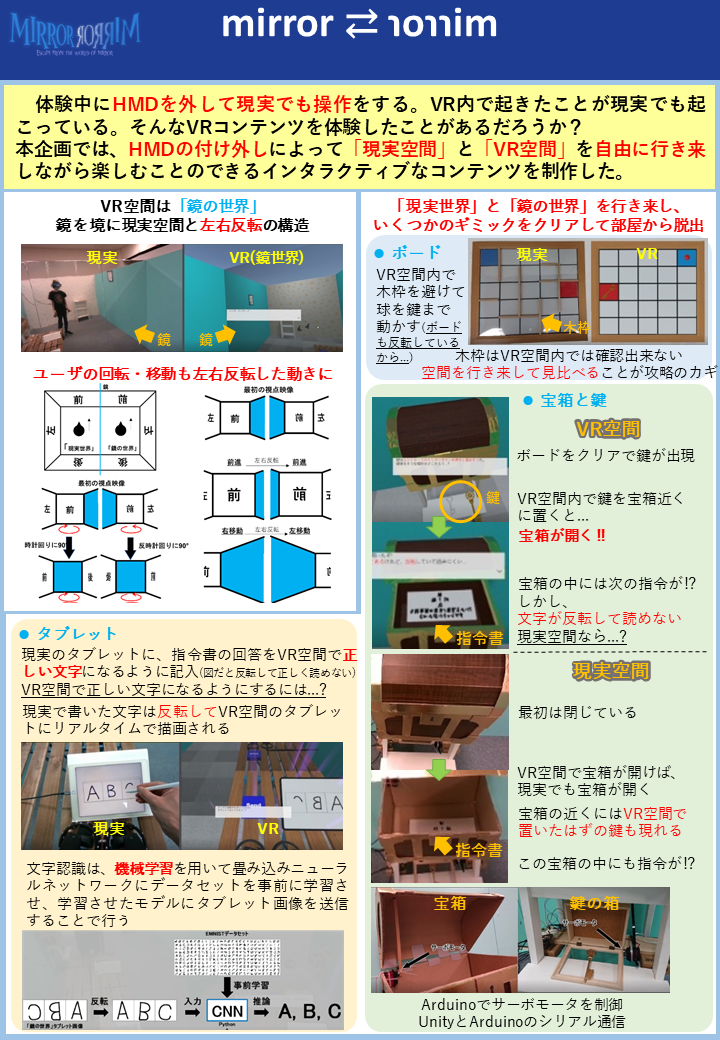
mirror ⇄ ɿoɿɿim
1つ目は「mirror ⇄ ɿoɿɿim」という作品です。
本企画では,一般的なHMDを装着したまま終始VR空間内で体験するコンテンツとは違い,現実空間とVR空間の両方の空間を使用するコンテンツ体験を目指し,HMDのつけ外しによる「現実世界」と「鏡の世界」の自由な行き来が積極的に呼び起こされるコンテンツを制作する.「鏡の世界」において行動感覚の左右反転などの現実では不可能なVRならではの感覚を提示することで,プレイヤーは現実空間とVR空間の行き来の中で現実空間の感覚とVR空間の感覚の違いを強く感じ,特殊なVR空間への没入感が増幅される.また,「現実世界」と「鏡の世界」が相互に影響していると感じさせることで,現実空間とVR空間の両方を楽しむことのできるコンテンツ体験を可能にする.
ポイントとしては、
- HMDの付け外しを誘発することによって現実空間、バーチャル空間の両空間を行き来する体験
- オブジェクト配置位置の異なる空間でも移動感覚提示方法を変化させることによって、空間間の整合性を保つ仕掛け
の2点だと考えています。
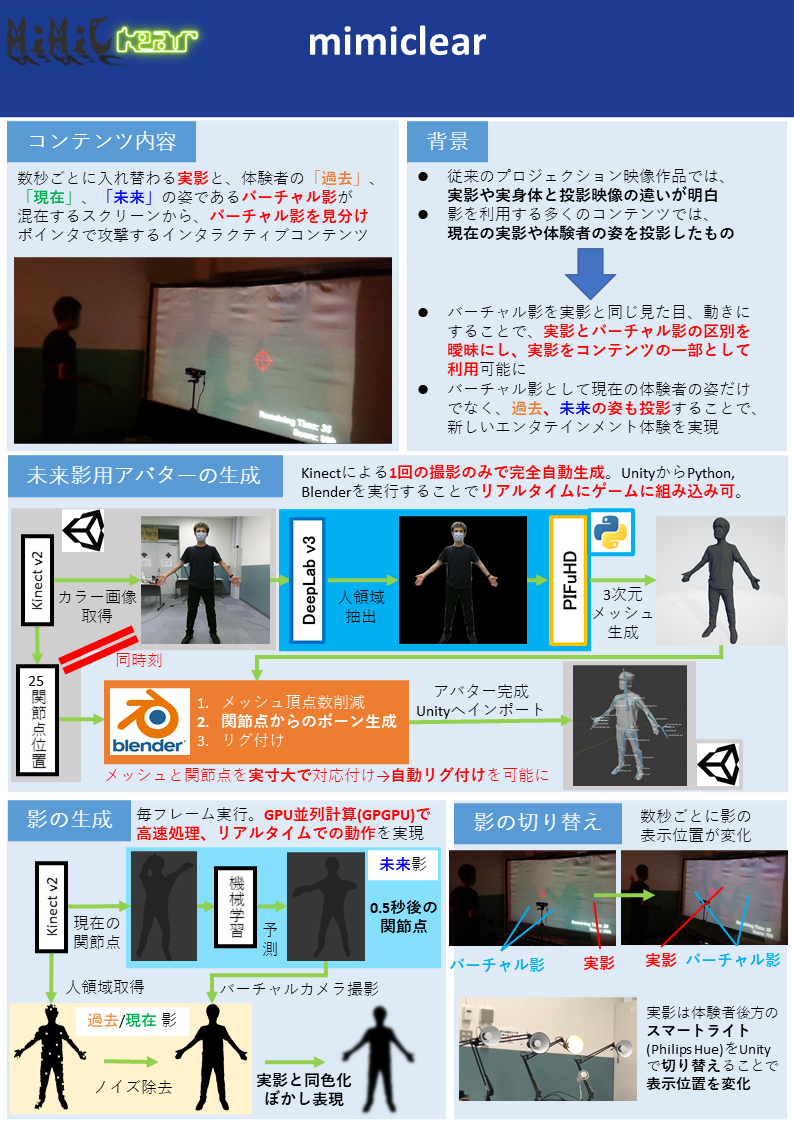
mimiclear
2つ目は「mimiclear」という作品です。
本企画はプレイヤーの体から出る普通の影とプロジェクタによって投影されるバーチャルな影が混在するスクリーンで影とのインタラクションを楽しむコンテンツである.バーチャル影はプレイヤーの影と全く同じ見た目,動きをするためプレイヤーはスクリーンに映る影が自分自身の影かバーチャル影かがわからなくなり,プレイヤーの影もインタラクションできるコンテンツの一部として利用可能になる.また,バーチャル影として「過去のバーチャル影」「現在のバーチャル影」「未来のバーチャル影」を投影することで,過去・現在・未来という違う時点の自分の姿とインタラクションでき,従来のプロジェクションコンテンツにはない時空を超えた体験を可能にする.
ポイントとしては、
- バーチャルな影だけではなく、実影も利用するように組み込んだコンテンツ
- 過去・現在だけでなく、機械学習を用いた未来の姿勢推定を用いたコンテンツ
の2点だと考えています。
リモートでの開発
企画書選考を行っているうちに必要なタスクを洗い出し、それぞれのタスクの担当を決めました。 それぞれ、やりたいことを優先しつつ、概ねそれぞれが得意な領域で貢献できるようになったと思っています。 役割分担は以下のような形でした。
- mirror ⇄ ɿoɿɿim
- mimiclear
開発もコロナ渦ということもあり、ほとんどリモートでの開発でした。 GitHubでコードを共有しつつ、ある程度機能ができるごとにプルリクエストを出してレビュー → OKならマージという一般的な形で進めていました。 最初チームメンバー3/5人がGitHubを知らなかったですが、最初に講習をおこなって使い方を教えたら最低限pushとプルリクはしてくれました(優秀なチームメンバーに感謝)。 ただ、いきなりCLIのコマンドでの操作はハードルが高いと考え、GitHub Desktopを使う形で講習しました。
講習スライド一部抜粋↓


週一で各自の進捗や問題点を話すミーティングをしつつ、リアル/対面でないと確認できない確認作業や、プロトタイプテストでは数回集まって開発を行っていました。 研究室がGatherを導入しているため、作業している時はGatherをつけっぱなしで作業して、気軽に話せる環境になっていたと思います。
プロトタイプテストをしている様子↓
(mimiclearのバーチャル影を実影に似せる方法を模索していた)

個人的に大変だった実装
mirror ⇄ ɿoɿɿimのコントローラ位置補正
mirror ⇄ ɿoɿɿimでは、VRで鏡の世界の移動感覚提示を行うために、鏡と垂直な方向の移動と高さ方向の回転については、通常のVRシステムとは反転しています(詳しくはこちら)。 すると、当然VRコントローラは右手コントローラが左手位置に、左手コントローラは右手位置にくるのが鏡空間としては正しいわけです。 しかし、これは非常に操作がしにくいので、右手コントローラが右手位置に、左手コントローラは左手位置にくるように修正しています。 具体的には、通常のVRシステムでのカメラ座標系でのコントローラ相対位置を、鏡カメラ座標系での位置にしてあげるだけです(悩んだあげく結構簡単)。
// Update()でカメラの位置計算を行うので、LateUpdateを使うことで鏡世界カメラの位置を取得可能に
void LateUpdate()
{
// 基本的にコントローラの回転はそのまま取り込むが、Y軸回転のみ鏡カメラの回転と整合をとる
var mirrorRot = originHand.rotation.eulerAngles;
mirrorRot.y += mirrorCamera.rotation.eulerAngles.y - originCamera.rotation.eulerAngles.y;
mirrorHand.transform.rotation = Quaternion.Euler(mirrorRot);
// HMDオリジナルカメラ座標系でのコントローラ相対位置を、鏡世界カメラ座標系に反映。
// 鏡世界だと本来は右手に左手コントローラを持つようになるが、コントローラのみは通常世界の持ち方を反映する
var originCameraRelative = originCamera.InverseTransformPoint(originHand.position);
var mirrorPos = mirrorCamera.TransformPoint(originCameraRelative);
mirrorHand.transform.position = mirrorPos;
// 鏡世界の本来の位置計算は
// var mirrorPos = originHand.position;
// mirrorPos.x = -mirrorPos.x;
// mirrorHand.transform.position = mirrorPos;
}
mimiclearの複数影
mimiclearのバーチャル影はKinectから渡される人領域情報を使っているのですが、Opening&Closing処理をすることにより影領域内の穴(欠損ノイズ)を埋めています。 また、ガウシアンフィルターによるぼかし処理もすることで、実影に似たソフトシャドウ感を出しています。
これが複数の過去、現在、未来影1つ1つに行われているため、高速化するために上記の処理をGPGPUで自前実装しています。 テクスチャデータ管理をしっかりしないとメモリを食い尽くして体験中にUnityが落ちるので、メモリ節約作業がなかなか神経を使う作業でした。
過去、現在影による複数影実装ができて1人ダチョウ倶楽部をしているIKEP↓

ぼかし実装

mimiclearの完全自動リアルアバター生成
未来の姿勢推定、人の姿のmesh生成(PIFuHD)は既存の機械学習手法でできるということがわかっていたのですが、meshを推定した姿勢にするにはmeshがリグ付けされたアバター(Humanoidモデル)である必要があります。 これを行うためにUnityとBlender、Kinectからの情報を使って完全自動リグ付けパイプラインを自前実装しました。 詳細は上述した動画に載せている通りなのですが、また別途記事を書きたいと思います。
追記: 完全自動リアルアバター生成の記事を書きました。
ikep.hatenablog.com
SEED STAGE
書類選考を通過した作品はSEED STAGEで審査員の方々に体験してもらう「体験審査会」が行われる予定でした。 しかし、2021年8月ごろにおけるCOVID-19の感染拡大状況では厳しいとの判断で、動画でのオンライン審査になりました。 関係者のみの非公開なYouTubeライブで参加者が提出した作品説明動画を見て、審査員の方々がリアルタイムにコメントをしていくような形でした。
また、SEED STAGEでは日本VR学会でのポスター発表も行いました。 Binaural Meetというツールで、ポスター画像の近くにいる人どうしで音声会話でコミュニケーションをとる形でした。
#IVRC2021 映えるMeet(正式名称BinauralMeet)この景色もそろそろ見納め pic.twitter.com/xUiVTnTKdk
— Dr.(Shirai)Hakase/Metaverse R&D Director/REALITY (@o_ob) 2021年11月6日
学会での発表という形をとっているので、当然学会発表原稿も書いており、文書として記録に残るのはありがたいことだなと。
Binaural Meetでは、いろいろな協賛企業の方や他チームの方とのコミュニケーションができるので、何を考えて作ったのか、なぜその方法で開発したのかなど、書類や映像だけでは伝わらない工夫点や苦労を話せたのもいい体験でした。 (それ以外にも個人的には、過去にインターンなどでお世話になった企業さんや他チームの知り合いとのコミュニケーションも取れたので、)コミュニティとしてのIVRCのすごさを感じました。(この繋がりを大事にしていきたい...)
SEED STAGEでは協賛企業様による企業賞が決まるのですが、結果としてmirror ⇄ ɿoɿɿimがUnity賞を、mimiclearがteamLab賞を受賞しました🎉 (2作品とも受賞で、チームメンバーと一緒に研究室で舞い上がって喜んでいましたwww)
#IVRC2021 Unity賞
— IVRC公式アカウント (@IVRC) 2021年9月14日
"mirror ⇄ ɿoɿɿim"
M.W.I(関西学院大学,関西学院大学大学院)
「エンターテイメントとして面白いものを選定、体験のセットの作り込みが素晴らしかった。Unityグッズを人数分プレゼント」 pic.twitter.com/ACnMX5kbZx
#IVRC2021 teamLab賞
— IVRC公式アカウント (@IVRC) 2021年9月14日
"mimiclear"
ドッペルマン(関西学院大学)
「新規性、技術力、社会有用性、やってみたさ、を基準に選定。影の予測を作る技術力、影の境界を認識する経験があとに続く体験になるのではないか、という点評価」 pic.twitter.com/xZ2otjKD0X
Unity賞の副賞↓

LEAP STAGE
LEAP STAGEは関東と関西での分散しての体験審査でした。 それぞれのチームが大掛かりな荷物を持ってきて設営→体験展示→撤収という、(コロナ禍前の)例年のIVRCの(文化祭的な)空気感があって懐かしかったです。 個人的には、mirror ⇄ ɿoɿɿimの壁(1.8m × 1m)を12枚運ぶ&2作品展示というのもあり、搬入と設営には体力気力ともに限界に近い1日でした...😅
#IVRC2021 体験会終わった…
— IKEP (@CreativeIKEP) 2021年10月30日
細かいトラブルはあったものの、ちゃんと動いて体験してもらえてよかった…
(1日の設営、展示、片付けを2作品は疲労が…😩)
展示中も(mimiclearの照明の関係で他チームに迷惑にならないように)2作品を同部屋で展示したのですが、2作品同時に体験ができないため、審査員の方々や体験したいと言っていただいた方に非常にお時間とご迷惑をおかけしてしまいまいました(すみませんでした...)。 そのほかにも、利用しているソフトフェアのバグ?(SteamVRがVRデバイスをいっさい認識しなくなって焦った...)でトラブったりとバタバタして、ここ数年で一番大変だった1日でした。
しかしやはり、体験していただいて初めて面白さが伝わることもあり、そこから技術話になったりと大変ながらも本当に楽しい1日でした。 また、他のチームの作品を体験することもできたので、様々な刺激をもらうこともできました。
後日、オンラインでの審査会と表彰式が行われました。 審査会では、各作品ごとに動画を見た後、Q&Aにて体験会や動画を踏まえた質問に対して私たち参加者が答える形でした。 審査会と表彰式の様子はYoutubeで公開されているので、ぜひご覧ください↓
審査の結果、なんと「mirror ⇄ ɿoɿɿim」が2位にあたるVR学会賞を受賞しました🎉
- 表彰式でのmirror ⇄ ɿoɿɿim: 4:35:37~
VR学会賞、総合2位!!
— IKEP (@CreativeIKEP) 2021年11月6日
本当に、本当にありがとうございます!😂
体験デザイン、モデリングデザイン、ハードウェア、プログラムとチームメンバーそれぞれの得意分野を存分に発揮できたからこそ、ここまで来れました!
IVRCの皆様、チームメンバー、ありがとうございました!!#IVRC2021 https://t.co/EO54vKN4C7
制作&参加してみて
結果として2作品合わせてですが、準優勝にあたるVR学会賞と、Unity賞、teamLab賞と3つもの賞をいただき、高く評価していただけて、すごくうれしく、貴重な経験をすることができました。 最初はなんとなくで参加しましたが、思い切って飛び込んでいくことはやっぱり大事だなと再認識しました。
また、結果論的かもしれませんが、個人的にはmimiclearはmirror ⇄ ɿoɿɿimよりも技術的に高度なことをやっていると思っていますが、mirror ⇄ ɿoɿɿimがVR学会賞を受賞しています。 mirror ⇄ ɿoɿɿimは体験のデザインだったり、モデリング、ハードウェアと、チームメンバーそれぞれの得意な能力を発揮できたと思っており、だからこそ高い評価をいただけたのかと思いました。 なので、やっぱりチームでモノづくりをすることは大事だなと感じつつ、今後チームメンバーの能力も引き出すことができるような人間になっていけたらなと感じました。
さらに、冒頭にも書きましたが、自分は2017年参加時に落ち込んでから、いろいろなところで勉強や経験を積ませていただいたおかげで、大きく成長できたし、今回の結果につながったとも思うので、多くの人に感謝し今後もその繋がりを大事にしていきたいと思います。 IVRCのコミュニティとそれに関わる多くの方々に感謝します! ありがとうございました!
(後日談)
teamLab賞の副賞がteamLabさんの展示に招待とのことだったので、チームメンバー全員で見学させていただきました! チームメンバー全員で行ったので、修学旅行感がすごかったですw
IKEPは以前インターンでお世話になったことがあるため、案内をしていただいた社員さんとはお久しぶりでした(笑)
ご招待でプラネッツとボーダレスに行ってきました
— IKEP (@CreativeIKEP) 2021年11月26日
teamLabさん、ありがとうございました! pic.twitter.com/mo9Vtsg5oL
1人で1年かけて、ARでつながる新時代SNS「Treadraw」をつくった

タイトルにある通り、たった1人の個人開発で約1年をかけ、ARでつながるSNS「Treadraw」を制作しました。
その制作の話をしたいと思います。
ダウンロードはこちらから↓

Treadrawとは?
「トレドロ」と読みます。
ARを使って現実世界にお絵描きしたり、メッセージや画像などを置き、それらを空間ごとシェアすることができるSNSアプリです。
お絵描きなどのAR物体は現実空間にずっと残すことができ、他の人も同じ場所で同様のAR体験を共有できます!
現実空間にあなたの思い出の足跡を残すことができる新しいSNSなのです!
動画はこちら↓
Treadrawの名前の由来は?
treadとdrawの二つの英単語を組み合わせた造語を作品名にしました。
treadには踏むや足取りなどの意味があり、drawには描くといった意味があります。
なので、思い出という足跡を描き残すという、このアプリのコンセプトを名前にしました。
アイコンもそのような思いを込めたものを作成しました。
作った理由ときっかけ
SFアニメなどで登場するホログラムなどの技術が研究開発されたりしていますが、この技術は将来的に街に溶け込むと思っています。
しかし、ホログラムの時代が来る前にARによる疑似的な表現がなされる時代が来ると思っています。
例えば、アニメ映画「ソードアートオンライン オーディナルスケール」のような世界です。↓
オーグマーと呼ばれるデバイスを装着することで、バトルシーンでは街の建物がゲームの世界観に合わせた見た目になっています。
このような街全体を対象としたARを現実的に実現する場合、ARCloudのような技術が必要になります(ARCloudの説明は割愛、興味ある方はリンクを見てください)。
しかし、世界中の場所を網羅したARCloudデータはありませんし、僕の知らないところで存在していたとしても、今の時代において個人に貸してもらえるとは到底思えません。
なので、こういった世界を実現してみたいと思っていましたが、まだ無理かな~と思っていました。
そんな中約1年前、AppleのARKitの機能の一つのARWorldMapを知り、ARデータ(カメラが捉えた点群データ)を端末内に保存し復元できることを知りました。
ARCloudのようなデータがなければ、各ユーザに点群データを集めてもらえば良いのではないか?
ARWolrdMapの機能を応用することで、↑のようなことに挑戦しようと思い制作したのがTreadrawです。
コンテンツに落とし込む
私はせっかくやるなら、作品にしたいと思いました。
できたものをTwitterで言うだけ、ブログに書くだけ、デモシステムの作成などではなく、作品として世の中に発信し、新しい価値観に触れてもらいたいと。
いろいろ考えた結果、自分はクラウド技術を使ったシステム制作の経験もあるため、その経験を活かせるSNSの作品とすることで、空間を「投稿」としてシェアする作品にしました。
ちょうど、InstagramのARバージョンといったような感じをイメージしてました。
ARWorldMapはARCloudなどと違い、現実世界の一部分しか捉えることができない欠点があります。
しかし、「投稿」という形態とGPSを併用し、「現実空間の中でARオブジェクトを探す」ことで乗り換えました。
これにより、今までの写真でシェアするSNSの概念を残しつつも、同じ場所にいる or 来た人は空間もシェアし、時間を超えた体験の共有ができる新しい作品に落とし込むことができました。
制作
使ったもの
C#、Swift、Objective-C、Python、HTML/CSS、JavaScript
Unity、Xcode
Google Cloud Platform、Firebase、Apple ARKit、Django
前述したAppleのARKitの機能のARWorldMapを使用するので、UnityでiPhoneアプリとして制作しました。
SNSなので当然、バックエンドが必要ですが個人開発なので、開発コスト(費用も)を考え、firebaseを利用しました。
全体のシステム構成は↓のような感じです

このアプリのコアである、AR空間の共有(SNSシェア)↓のような感じです

端末内に保存されているARWorldMapデータを取り出して、データベースに保存しています。
加えてRealtime Databaseで、GPS・投稿の詳細情報とCloud Storage上のARデータを一緒に管理することで、投稿位置情報に基づいた空間体験共有を実現しています。
約1年の制作で学んだ、長期制作の辛さ・苦労点
ライブラリのバージョン変更やバグ
完成したものでは、約10個近くのライブラリを使用させていただいております。
しかし、それらのライブラリもアップデートが起こります。
これは、ライブラリが開発者様によってメンテナンスされているので非常にありがたいことなのですが、Unityで使用するライブラリは一部手動で差し替えなければいけません。
また、バグが発生し解決されるまで時間がかかることがあります(メンテナンスされていないライブラリだったら自分でデバックするしかない...泣)
最も痛手だったのは、UnityでARKitを使うためのプラグインが制作中に非推奨になってしまったことです。
Unity-ARKit-Pluginが非推奨になり、Unity標準のAR Foundationの使用を推奨されました。
これにより、AR機能のプログラムの大幅な変更を余儀なくされました(´;ω;`)
プラグインがバグってるから公式のを見に言ったらえぐいことが書いてあった。
— IKEP (@CreativeIKEP) October 7, 2019
もうすぐ完成やったのに...
泣きそう... pic.twitter.com/yW7ks8SMbu
Unityアップデートでのバグ発生
Unityのアップデートによってバグが発生することもありました。
そもそも、制作中のものなのにUnityのバージョンを変更するべきではないというのは当然だと思うのですが、使用しているライブラリのアップデートによってUnityのバージョンを変更しなければならなくなりました。
↑で言ったAR FoundationもUnityアップデートの一例です。
大規模ネットワークデータへの対応
これは僕の能力が劣っているだけかもしれませんが、SNSのデータをどのように管理するかに悩まされました。
多くの人が利用しかつお互いのデータを共有するため、システム実装面とセキュリティ面を同時に考慮する必要がありました。
また、将来的に機能を追加する場合でも問題ないかなど非常に神経質に考える必要があり、苦労しました。
TwitterやFacebookなど大規模ネットワークがいかにすごいシステムなのかを感じましたね...
世間の流行の遷移
技術の進歩は日進月歩、というのは本当だと思います。
長期の制作をしていると、新しい技術や流行が作られたり遷移したりします。
私の場合、制作開始約3か月後にMicrosoft Azure Spatial Anchorsが発表され、iOS、アンドロイド、HoloLensとプラットフォームに依存しない点群データ共有のサービスが発表されました。
これにより、自分の制作物が受け入れられるのかという不安になりました。
U-22プログラミングコンテスト2019に応募してみた
制作中にβ版ぐらいのものができたときに、他人がどう思っているのかを聞きたかったので、U-22プログラミングコンテスト2019に応募しました。
757作品の応募があったようですが、ありがたいことにベスト40作品に選出していただけました🎉
審査員の方からのコメントは、お褒めの言葉から自分では気づかない着眼点のアドバイスなど、非常にありがたいお言葉をいただきました。
そのうちの一部はすでにリリース済みのものにも組み込んでいます。
今後
正直、現在リリース中のものは最低限の機能のみだと思っています。
自分の中で拡大させたいユースケース案や追加機能を考えているので、これからもっとTreadrawを進化させていきたいと思います!!
Treadrawのこれからの進化を楽しみにしていただけたら幸いです。
ぜひ、ダウンロードして思い出の足跡を残してみてください ^^) ~~
追記
2020/9/26に開催された学生エンジニアのアウトプットを発表する技術カンファレンス「技育展」で、Treadrawを題材にスマホアプリ枠で登壇し、プレゼンテーションをさせていただきました!SNSなので、多くの人に認知してもらう必要があると考え、参加させていただきました。
発表スライドも載せておきます!↓
チームラボのインターンに行ってきた(インタラクティブチーム)
2019/09/02~2019/09/13の2週間、チームラボ株式会社のサマーインターンに参加させていただきました。
そのインターンでのことをまとめたいと思います。

チームラボ株式会社とは
チームラボは、メディアアートやweb開発、モバイル開発など様々な制作・開発を行なっている会社です。 採用ページなどで見かける「ウルトラテクノロジスト集団 チームラボ」というように、様々な分野のスペシャリストの方がいらっしゃるようです。 インターンで参加できるコースも12コースほどあり、私はインタラクティブチームに参加させていただきました。
チームラボとの出会い
チームラボの名前を知ったきっかけは、2年前参加したVRの国際コンテスト(IVRC2017)に出場した時でした。 このコンテストにチームラボが協賛しており、自分の作品を社員の方が体験していただけたことがきっかけです。 自分は高校生のころ映像制作などの芸術と技術が融合したものを作りたいと思って今の大学に入学したので、チームラボが制作しているメディアアート作品をwebで見たときは「まさに自分が追い求めているもの」と非常に驚いたのを覚えています。
インタラクティブチーム
インタラクティブチームは、このメディアアートなどを制作しているチームです。 一番最初に乗せた写真↑、teamLab Borderlessのビジュアル部分を制作しているのも、このチームです。
インターン応募
インターンの選考は、エントリーシートによる書類選考後、面接でした。 面接は、参加希望するコースの現場エンジニアの方とお話したので、技術話で盛り上がりました。
僕がインターンにいく理由としては、
- 会社自体や利用している技術に興味があり、現場を見たい
- 将来の就職先として考えている
と大きく2つです。 他に参加したインターンの大体は前者なのですが、チームラボは両方の動機がありました。 だから、どうしてもインターンに行ってみたかったのです。 (実は、今回インターンに参加する前に2回応募しているのですが、2回とも書類選考で落とされています...笑)
インターンの内容
インターンでの内容は初日の日にメンターの社員さんと相談して決めました。 何か作りたいものがあるか、何をしてみたいかなどを話し合い、2週間で制作するものを決めました。 僕の場合、インターンの間にやりたいと思っていたこととして、「シェーダーを使えるようになる!」と言うことを考えていました。 しかし、シェーダーで何を作りたいかがその場で思い浮かばなかったので、開発中のARペイントアプリでも使えそうな、「自作のブラシエフェクトを作ろう!」となりました。 また、VRペイントアプリケーション「Tilt Brush」とかでは、アニメーションをするブラシが少ないと言うことだったので、アニメーションするブラシもできたらいいよねとなりました。 最終的に、「アニメーションブラシエフェクトに凝ったVRペイント」を作ることにしました。
今回のインターンの期間に大きく分けて3つのブラシを作成できました。 最終的な作品がこちら↓
インターンで作ったものを自分の成果物にしていいよとのことだったので、GitHubでソースコードは公開しています。
最終日には、インターン生が2週間の成果を発表する機会があったので、その時に発表もしました。 そのスライドも載せときます!↓
インタラクティブチームインターン生としての感想
開発中はほとんど見た目のディテールにこだわることをしており、ブラシの線の太さやペイントスピードなどが変わっても、見た目のディテールに影響しないように調整するのが大変でした。 やはり、世界中から高い評価を受けるアートを作っている会社であるだけに、豊富な技術力やノウハウを持っていることを実感しました。 実装方法に悩んだり勉強したいことがあれば、サンプルプログラムを見せてもらえたり、オススメの本を教えてもらえたりしました。 また、週一で短い時間ですが、インタラクティブチームの勉強会があったり、今やっている仕事の内容や工夫点を共有していたりと、ありとあらゆる場面で学ぶことができる環境だったと思います。 さらに、ランチはインターン生とチームメンバーで行こうとしていただけたため、インタラクティブチームで働くのはどんな感じかといったことから、展示している作品の技術的な話まで様々な話ができ、学べることが非常に多い環境でした!!
インターン毎日学ぶこと多くてかなり楽しいけど、その分インプットする知識が大量なので夜は疲れてる(普段がのんびりしすぎなだけ 笑)
— IKEP (@CreativeIKEP) 2019年9月4日
チームラボのインターン生としての感想
インタラクティブチームではなくチームラボのインターン生としても非常に楽しい働ける環境でした!
初日と最終日にはインターン生全員と社員さんで懇談会があり、他のインターン生や社員さんと話すことで刺激が多いです。 自分の知らない分野の技術話を聞いたり、チームラボ働いてみてどうかとかなど多くのことを話せました。 一方で自分の技術話も理解してもらえて通用するのも非常に嬉しかったです。
チームラボインターン最終日懇談会めちゃクソ楽しかった
— IKEP (@CreativeIKEP) 2019年9月13日
技術話が深掘りしてここまで話せる環境はなかなかない pic.twitter.com/T1blgtYI9V
採用チームの方とランチする機会があった時に、前述したIVRCの話ができたのも記憶に残っています。 今年のIVRC予選が、インターン期間中チームラボオフィスの近くで開催されたこともあり、自分が出場した時の話もできました。
VR学会&IVRC行きたかった...
— IKEP (@CreativeIKEP) 2019年9月11日
せっかくインターンで東大の近くにおるのに...
今日から #IVRC 予選
— チームラボ 採用 (@teamlab_recruit) 2019年9月11日
学生が企画・制作したVR作品を競う大会に協賛しています。決勝へ進む作品(https://t.co/ckq1VDimdS)は果たして!?
我々は13日に参戦予定です。是非お声がけください🙇♀️
ちなみにteamLab は通年でアルバイトを募集しています。学生さん大歓迎!!https://t.co/Zcq4Jv96x3 pic.twitter.com/8yQdoQ7kfc
インターンの待遇
チームラボのインターンはインターンの経験だけでなく、待遇も非常に素晴らしくありがたいものでした。 まず、インターン期間中は時給1000円が発生しており、お給料がもらえます。 (他のチームは実務やってるとこもあるけど、インタラクティブチームは実務してないのに....。感謝感激😂)
また、交通費、宿泊費も全額支給してもらえます。 特に宿泊に関しては、インターン開始前日から最終日翌日まで、オフィスまで徒歩10分のホテルをチームラボ側で予約していただけました。 そのため、初日の朝早くや最終日の深夜に新幹線に乗ることもなく、初日前日にゆっくり行ったり、最終日翌日に観光したりもできました。
また、インタラクティブチームインターン生としてはめちゃくちゃ嬉しいteamLab Borderlessの見学会もありました。 自分が今(インターンで)いる場所はこの作品が生み出されている場所だということ、自分が学んでいるその先にこのような作品を作れる可能性があること、などを考えたら鳥肌が立ちましたね 笑
本日のお仕事#チームラボボーダレス見学会 pic.twitter.com/2t24BdXpA5
— IKEP (@CreativeIKEP) 2019年9月6日
まとめ
一言でいうと、「クリエイティブに没頭できる最高の2週間」という言葉が全てを物語っていると思います!! 様々な人と出会い交流しつつも、自分の専門を深め非常に多くのことを吸収できる環境が整っていると思いました。 何より、自由に好きなことで働けるということが実感しました。 もっとこの環境でいたかったと心の奥底から思うほど、チームラボのインターンに参加できてよかったです! チームラボのみなさま、インターン生のみなさま、ありがとうございました!!m( )m
敵対的生成ネットワークをまじめに勉強して実装してみた2 ~CycleGAN~
前回、概念から数学的なことも含めてGANについて説明しました。
今回はCycleGANにフォーカスを当てます。
 CycleGANの論文より
CycleGANの論文より
CycleGANとは
画像から画像への変換が可能なGANの一種です。 こういった画像to画像の変換にはpix2pixのように、データセット画像がペアになっているのが普通です。 「入力画像に対して画像変換を行うとこういう画像になる」という風に、入力画像群と変換目標画像群をペアにして与えます。
しかし下の画像のようなペアではないものでも、CycleGANは画像間のスタイル変換が行えます。 なので、上の画像のように現実的にペアの画像を用意することが難しいものが対象でも画像変換が可能です。 (馬とシマウマを全く同じ構図、背景、姿勢で写真を取るのはほぼ無理ですよね?)

工夫点
ペアの画像の場合は入力画像と変換目標の画像間のピクセルごとの差分を利用する(MSEやMAE)などで、学習を進めることができます。 しかし、今回はペアでないものを対象とするための工夫がなされています。 それは、2つのGenerator(G, F)を用意し、Gで変換したものをFで変換した時に、元の画像に戻るかという設計です。 ドメインXの画像群の画像xをGによってドメインYの画像群のような画像y^に変換。 その後、y^をFでXへと変換した画像x^が、xとどれだけ異なっているか利用しています (数学的にいうと、X→Yの写像GとY→Xの写像Fがあり、Xの画像xを入力した時、x-F(G(x))の値を小さくする、ということ)。 これが、Cycle Consistency Lossと言われています。

損失計算
損失関数は以下のようになっています。

で、Cycle Consistency Lossがどれかというと、上式の3項目です。 内容は以下

画像ドメインX, YそれぞれのCycle Consistency Lossの和です。 L1ノルムなので、ただピクセル間の差分を見ているだけですね。
そして、残りの1, 2項目は以下のようになっています。

GeneratorがDiscriminatorを騙せたかどうかということです。 これは、普通のGANとAdversarial Lossと同じなので、説明は割愛します。
λは、Cycle Consistency LossとAdversarial Lossの割合を決めるハイパーパラメータで、論文の実装では10で実装したとなっています。
実装してみた
てことで、内容は理解したのでChainerを使って実装してみました。 実装したコードはこちら。 データセットは公開されているものの2つ(馬↔︎シマウマ、りんご↔︎みかん)と、オリジナルで作成したものを利用しました。 オリジナルは、ポケモンのモンスターボール↔︎マスターボールの変換です。 google-imagedownloadを使って、Google画像検索で出てくる画像を使いました。(そこから明らかに違う画像は人力排除...)



学習結果
馬↔︎シマウマ

りんご↔︎みかん


モンスターボール↔︎マスターボールでいい感じのやつを集めてみました↓。 特に左上がMマークが作成されてるので、ちょっとびっくりしました。




感想
ペアデータなしでここまでの画像変換ができるのは、かなり感動です。 論文の画像を見る限りではもう少しクオリティが高そうだったので調べると、今回実装したコードは学習安定化のテクニックを入れていなかったので、それが原因かなと思います。 でも、楽しむ分にはなかなかな精度が出てるのでいいんじゃないでしょうか(^ ^)
参考
[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
敵対的生成ネットワークをまじめに勉強して実装してみた
敵対的生成ネットワーク(Generative Adversarial Network, GAN)を使うことになったので、いろいろ勉強しました。せっかくなので、備忘録として勉強したことをまとめておきたいと思います。これから、GANを勉強する方の参考にでもなればと思います。
GANとは
Generative Adversarial Network(日本語では、敵対的生成ネットワーク)と呼ばれるディープラーニングを用いた生成モデルの一種です。
GeneratorとDiscriminatorという二つのニューラルネットから構成されており、二つを敵対させながら学習を進めることで、高精度なデータを生成することができるようになります。
よく、説明される例を挙げると、偽札屋と警察の関係に似ています。偽札屋(=Generator)は警察(=Discriminator)が本物と誤判別する偽札を作る。警察は、与えられたお札が本物の紙幣なのか、偽札なのかを見分けられるように学習する。警察の判別能力が向上すると、偽札屋はより本物そっくりな偽札を作らなければならず、偽札屋が本物そっくりな偽札を作れるようになると、警察はより高度な判別能力が必要となります。これを繰り返すと、偽札屋は徐々により高度で本物そっくりな偽札を作る方法を学ぶことができます。
このように、GeneratorはDiscriminatorを騙せるように、Discriminatorは与えられたデータが本物か偽物かを正しく見分けられるようにとお互いが敵対することで、最終的にGeneratorが本物そっくりな高精度なデータを生成できるようになるというのがGANの考え方です。

上図がGANの概念図です。潜在変数(VAEなどを勉強すればわかりやすいが、ここでは乱数と思ってOK)をGeneratorに入力し、偽物データを生成。DiscriminatorはGeneratorが生成した偽物データか本物のデータを受け取り、それが本物なのか、偽物なのかを判別、判別結果を出力します。
データとして画像を扱う場合は、GeneratorとDiscriminatorは大体、畳み込みニューラルネットワーク(CNN)がベースとなっています。
GANの学習
GANの損失関数は以下の通りです。

Dは0~1を返すDiscriminatorモデルの出力、GはGeneratorの出力(偽物生成データ)、zは潜在変数、xは本物データです。P_dataとP_zは確率分布でxとzがそれぞれの確率分布から生成されるとしています(詳しくは後述の「GANの数学的な考え方」)。
GANの学習アルゴリズムは以下の通り(GANの論文より引用)です。

GANの数学的な考え方
ここでは、GANの学習についてもう少し踏み込むために、GANの数学的な位置づけについて述べます。
前述したとおり、GANはディープラーニングを用いた生成モデルの一種です。ここでいう生成モデルとは、「データの生成過程を数理的にモデル化したもの」ということです。そして、数理モデルは確率分布によって表されます。つまり、何らかのデータは何らかの確率分布によって生成されると言えます。
簡単な例としてサイコロを考えます。サイコロを振った時に出る数字は、1~6どの面も1/6の確率です。これはつまりサイコロは、1/6の確率で1の目が、1/6の確率で2の目が...といったように、1~6すべての事象が1/6の確率である一様分布を確率分布とする生成モデルであると言えます。このように何らかのデータは何らかの確率分布によって生成されるといえることがわかると思います。
当然、Generatorはデータを生成するため、Generatorは暗黙的に何らかの確率分布を持っていると言えます。もちろん、学習に使う本物のデータ群も何らかの確率分布を持っていると言えます(上記の損失関数でいうところのP_data)。この本物データ群の確率分布にGeneratorの確率分布をできるだけ近づけていくというのが、GANの数学的な考え方です。
ここで損失関数を展開して計算します。

展開したところで、Gを固定してDの最適解について考えます。
ミニマックス問題なので、Dの最適解はVを最大化します。Vを最大化するには積分の中身を最大化すれば良いです。P_tとP_gは確率なので0~1、Dも0~1なので、積分の中身の式は、要は下のような上に凸なグラフになります。上凸なグラフの最大点が確率の割合でずれるだけと考えれば、Dで微分してやればいいです。

微分してやると

これが0になるDが最適解なので、式を整理してやると最適解は

となります。
次にこれを代入してGの最適解を考えると、

となり、最適なDのもとでのGの最適化は、Jensen-Shannonダイバージェンスの最適化に相当するということになります。
Jensen-Shannonダイバージェンスを軽く説明すると、2つの分布が距離としてどれだけ異なるかを測る尺度です。そして、最小値は2つの分布が等しい時で0になります。
つまり、Gの最適解ではVを最小化するのでPtとPgは等しく、V=-log4となります。よって、損失関数のGの最小化はPgをPdataに近づけることに相当し、本物データ群の確率分布にGeneratorの確率分布をできるだけ近づけていくことになるのです!
以下、イメージです(GANの論文より引用)。

ちなみに、Dの最適解

は、0.5となり本物と偽物を五分五分でしか見分けられないということになります。
実装してみた
以上のことをDCGANとして実装してみました。
GANの論文自体は、ネットワークの構成について一切述べていないので、DCGANを使いました。DCGANはGenerator、DiscriminatorをそれぞれFCNで実装したものです。
実装コードはこちら
データセットはgoogle-images-downloadを使い、Google画像検索で出てくるマリオの画像を使いました。ダウンロードした画像から個人目線で、マリオだけが写っている画像を手作業で抽出しました。その後、256*256pxに変換しています。

学習結果
個人的にいい感じで生成されていたのを抽出してみました。




初めてGANをやったので驚きです!!
もう少し綺麗な画像を出して欲しいけど、まあとりあえずここまでで 笑
参考
http://mizti.hatenablog.com/entry/2016/12/10/224426
https://qiita.com/triwave33?page=2
https://elix-tech.github.io/ja/2017/02/06/gan.html
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24
https://qiita.com/FrontPark/items/a591ad680dbb2589d4ba
https://www.slideshare.net/masa_s/gan-83975514
https://qiita.com/kzkadc/items/f49718dc8aedbe8a1bee
NAKEDのインターンに参加してきた
8/5~8/15まで約2週間、株式会社ネイキッド(Naked Inc.)の実務インターンに参加させていただきました。
そのインターンで学んだこと、感じたことなどをまとめたいと思います。
株式会社ネイキッドとは
NAKEDは、空間全体を演出するクリエイティブカンパニーです。
具体的には、映像による空間演出やインスタレーション、プロジェクションマッピングなどを行っています。これらの業界で有名なのは、チームラボとかですね。
元々はドラマのタイトルバックや、ミュージックビデオとかの制作を行っていたそうですが、最近は上記のような空間演出系のこともされているようです。
インターンに参加したきっかけ
僕は大学に入ってからプログラミングにハマり、色々開発・制作をしていますがVR・AR系の開発を結構しています。VRといえばHMDというのが今の時代だと思いますが、HMDの映像は3DCGです。さらに、ユーザーの行動によって映像が変化するのが普通なため、インタラクティブ3DCGです。僕自身もそういったHMDの映像を作っていました。その後、インタラクティブアートに出会い、自分がやっているVR/ARという分野に近いインタラクティブ3DCGによって、幻想的な空間が作り出せることを知り、いつか現実空間とコンピュータ世界の空間の境界を超えた作品を作ってみたいなと思っていました。
そんな中、テレビCMで興味深いものを目にしました。石原さとみさんが出演している、フレアフレグランスのCMです。
このCMの演出が面白いなと思い調べて見たら、花が舞うのは映像編集ではなくインタラクティブプロジェクションマッピングだったのです!
で、これを作っているのがNAKEDでした。NAKEDについて調べてみるとインターンシップを募集しており、
プロジェクションマッピング、AR(拡張現実)といった既存の表現にとどまらない空間を創造していきます。
映像表現がモニターのフレームを越えてリアルな空間に広がって行くにつれ、多様なデバイスをコントロールしたり、新しい表現の追求のために、それを実現するツールを生み出す技術が必要とされています。
と記述がありました。僕は「これだ!」と思い、すぐにインターンシップの応募をしました。
インターン選考
流れとしては、エントリーシート提出→面接→採用と一般的なものでした。
エントリーシートは、大学などの基本情報に加えなぜNAKEDのインターンに参加したいかを書いたと思います。
面接はSkypeで行っていただけました。NAKEDのインターンになぜ参加したいか、自分の経歴や経験はどんなものか、インターンで何を学びたいかなどありきたりな質問でした。
面接したその日のうちにインターンシップ採用のメールをいただきました。
テクニカルディレクター(メディアアートプログラマー)として参加することになりました。
業務内容
NAKEDは、大きく分けてblue、green、redの3チームに 別れており、blueが事務や企画(?)など、greenが映像の制作やインタラクティブ機能の作成など、redがNAKEDの核となるシステムの開発を行う、といったように別れているようです。
僕はredチームで働きました。概要としてはgreenチームの人が簡単に制作をできるようにするシミュレーションシステムの開発や、既存映像ツールでは制作困難なものをグラフィックプログラミングによって制作可能にし誰でも簡単に使えるツールにするなどを行いました。
インターンで学んだこと、感じたこと
-
オブジェクト指向のコーディングをもっと学ぶべき
-
-
インターフェースやイベントなど、オブジェクト指向の特性や能力をもっと生かしていくべき。そうすることで、クラス間の依存関係を薄めることや、機能拡張性、修正容易性が大幅に向上する!オブジェクト指向のコーディングをもっと学ぶには、既存の各クラスやメソッドを積極的に利用すべし。リファレンスを軽く眺めるのも1つの手。既存のものを利用すると、バグも少なくなり(リファレンスなどがあるため)誰にとってもわかりやすい。
-
汚いコードは読むだけで一苦労と痛感。結局何をしているかが伝わらないこともある
-
クラスを分けることで頭の中も整理できる
-
-
各クラスの役割を明確に定めることで、そのクラスで何を担当すべきか、データをどのように扱うが変わってくる。
-
-
-
様々な視点から書いたコードを観察する
-
-
エンジニアでない人が使うツールの作成を行ったために、どうすれば使いやすいか、人的なミスをなくし自動化できるかを、かなり考えた。
それにより、将来的に機能拡張をするときにどんなことが考えられるか、必要なデータがない時の処理やエラーハンドリングをどうするかなど、普段とは異なった視点からコードを観察できた
-
-
コーディングとリファクタリングを短いスパンで回す
-
-
コーディングをして一段落したら、放置せずに出来るだけ早くリファクタリングをすべき。コードが膨大になってしまうと、理想的な設計にするのは不可能だと思う。できるとしても、ほぼ作り直し
-
-
勝手に自分の中のフィルターを作らない
-
-
グラフィックの動き・綺麗さ、既存アルゴリズムの使用による限界など、「現状の手段では難しい」とか、「こんなものかな」など、現状に満足しないようにすること。何か少しでも気になるところがある場合は、何らかの解決手段を探し検討すべき。それが、繊細なところまでこだわりぬく事につながり、素晴らしい作品作りには不可欠である
-
繊細な調整や、処理負荷を考えられるのはエンジニアのみ。すなわちこだわり抜くことができるのもエンジニアにしかできない醍醐味。
-
- グラフィックプログラミング、GPGPUは面白い!
-
- パラメータ1つで出てくる絵が大きく変わることもあり、奥が深い
- GPGPUによって多量並列実行が可能であるため、膨大な量のシミュレーションが可能
→圧倒的な映像美をプログラミングで魅せれる
感想
コーディングに関しては、ほぼ自分で考え自分で思ったことばかりを書きましたが、やはり他の人にとって読みやすくするなり、他の人が使いやすいものにするなりと、他人を意識することで、良いコードが身についていくと思いました。
また、グラフィックプログラミング、グラフィックエンジニアリングの面白さを実感しました。想像している通りになるまでこだわり抜くこと、CGに関する知識や様々なツールを利用することで、未知なるものを生み出すことができると感じました。
僕もいつの日か、誰もみたことのない未知なるものを生み出してみたいものです...。